この記事は、CAST AI社により公開されたブログ記事を元に翻訳・作成したものです。元の記事については以下をご覧ください。
(記事最終更新日:2021年2月25日)
業務に最適なVMタイプを選択し、クラウド料金を節約する方法
公開日:2023年1月16日
更新日:2023年1月16日
アプリケーションの 90% が、実際に必要なリソースの 5 倍以上のリソースを持っていることをご存知ですか?* オーバープロビジョニングやクラウドのコスト削減は、まだあなたのデプロイメントにとって最優先の問題ではないかもしれません。しかし、クラウドの請求額が大きくなるにつれて、この問題は大きくなる可能性があります。
そして、CFOや財務チームからクラウド費用の配分方法について尋ねられた際に、適切に答えられるようにしておくべきでしょう。インフラの利用状況やクラウドのコスト効率について、しっかりとした回答が必要となります。
コンピューティングリソースは、クラウド請求書の最大の項目です。適切なVMインスタンスタイプを選択することは、クラウドリソースの最適化の重要な側面であり、場合によっては、コンピューティングリソース全体の請求額の50%を節約することも可能です。
既にVM の選択を最適化している場合は、我々のブログでさらなるコスト最適化のヒントをご確認ください。
クラウド利用料金の最適化は必要ではありませんか?
目次
*Christina Delimitrou および Christos Kozyrakis、「Quasar: resource-efficient and QoS-aware cluster management」
クラウドリソースの過剰プロビジョニングは簡単におこります
例えば、クラスタ用に4コアのマシンが必要だとします。CSPを1つだけ使ったシングルクラウドのシナリオでも、約40種類のオプションから選ぶことができます。
では、これらすべてのインスタンスを比較できますか?人間がこれらすべてのマシンタイプを理解して分析するのは難しすぎます。
例えば、次のAWSの料金表を見てください。
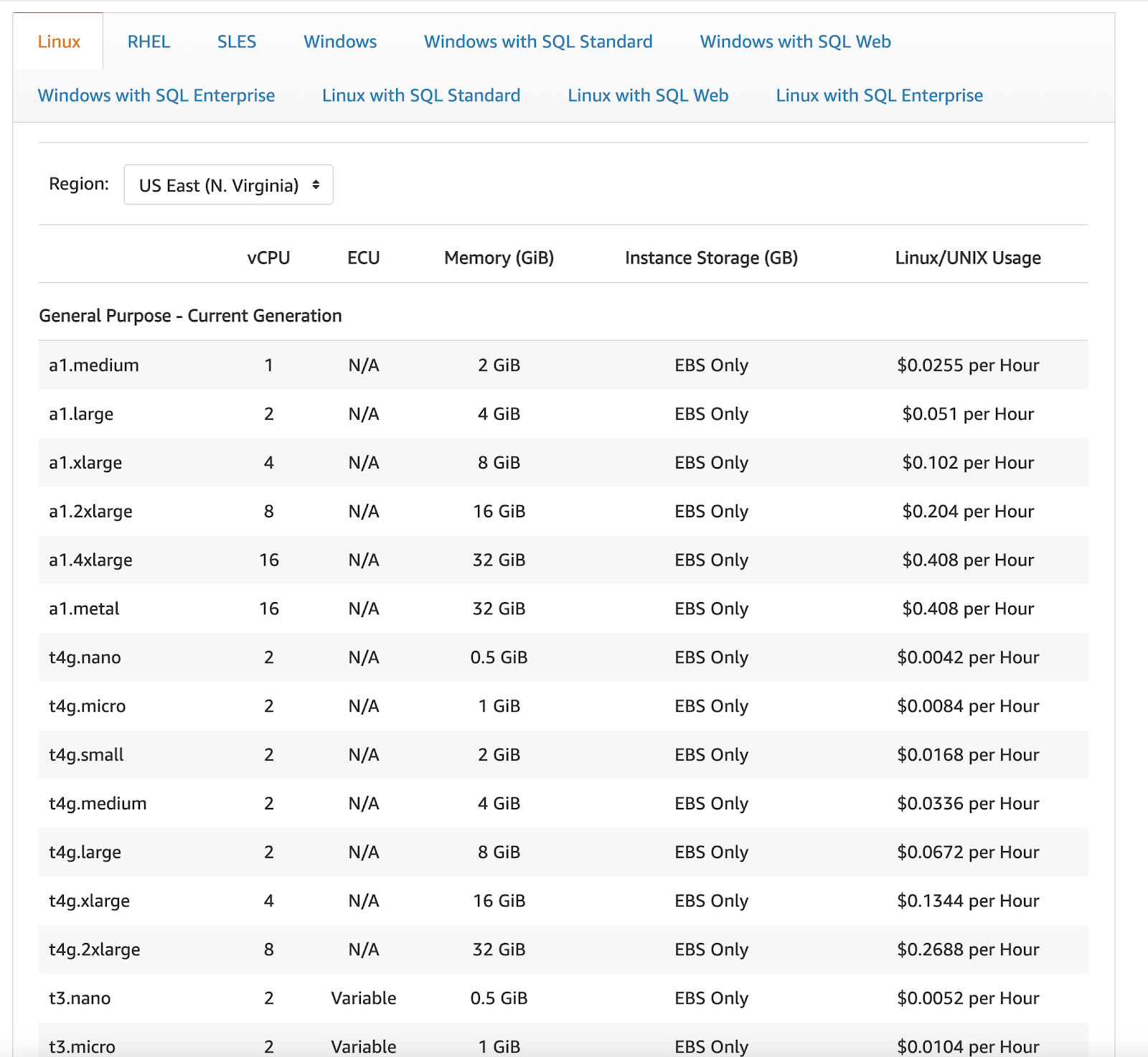
これは、あるリージョンの、あるOSタイプの一覧の一部でしかありません。
そして、この時点では、まだシングルクラウドの場合についてのみ話しています。マルチクラウドになると、これは指数関数的に複雑になります。
例えば、1時間あたり$0.19のインスタンスを選択したとしましょう。机上では妥当に思えたので、Infrastructure as Code(IaC)スクリプトを変更してデプロイします。
しかし、計算量の高いはずのアプリケーションをデプロイしてみると、そのアプリケーションは、あなたが支払っているほかのリソースを十分に活用できていないことにすぐに気づきます。ノードに割り当てられたメモリーは半分しか使っておらず、ネットワークも十分に活用されておらず、インスタンスに接続されたSSDさえも十分活用されていないのです。これでは、クラウドコストの削減を最大化することにはまったくつながりません。
CSPの提供物をもっと詳しく調べれば、もっと低コストでアプリケーションをサポートできる別のVMタイプを発見できたかもしれません。もちろん、メモリーやネットワークは少なくなりますが、今回のアプリケーションにとっては十分です。しかも、コストははるかに低く、1時間あたりわずか0.10ドルです。
このシナリオは作り物ではありません。これは、あるEコマース・アプリケーションのデモで実施したコスト/パフォーマンス・テストの結果です。この記事のさらに下にケーススタディがありますので、ご一読ください。
業務に適したVMを選択するための6ステップ
1.最低限必要なものを明確にする
クラウドコスト削減を念頭にしてVMインスタンスタイプを選択する場合、ワークロードは非常に重要な項目です。CPU(およびx86かARMか)、メモリー、SSD、ネットワーク接続を含むすべての計算機資源について、必要なものだけを手配するように努める必要があります。
逆に、手頃なインスタンスは魅力的に映るかもしれませんが、メモリーを多用するようなアプリケーションを実行するようになると、パフォーマンス問題に悩まされるかもしれません。
アプリケーションの最小サイズ要件を確認し、選択するインスタンスタイプがすべてのスペックで満たすことを確認します。
- CPU 数
- CPU アーキテクチャ
- メモリー
- SSDストレージ
- ネットワーク
アプリケーションの要件に合ったインスタンスタイプが決まったとしても、その「十分な」インスタンスタイプを購入することが必ずしも最善の選択とは限りません。例えば、異なるクラウド上の異なるVMは、価格と性能の比率が異なります。つまり、クラウドのコンピューティングコストに対してよりよいパフォーマンスを得て全体的なクラウドコストをより削減する可能性があるのです。
次に、CPUとGPUが密な関係を持つインスタンスの場合です。次のシナリオを考えてみましょう。
機械学習アプリケーションを構築している場合は、おそらく GPU 搭載のインスタンス タイプを探すことになるでしょう。それらはCPUよりもはるかに高速にモデルを学習させることができます。興味深いことに、GPUは当初、機械学習用に設計されたのではなく、グラフィックスを表示するように設計されました。
2007年、Nvidia はディープラーニングモデルの機械学習トレーニングで開発者を支援するため、CUDAを考案しました。今日、CUDAは、ほとんどの一般的な機械学習フレームワークで広く採用されています。そのため、MLモデルのトレーニングは、GPU を使用することでより高速に行うことができます。その仕組みを正確に知りたい場合は、詳細を掘り下げたこの興味深い投稿をご覧ください。
トレーニング済みのモデルで予測を実行する場合はどうでしょうか? 特化したインスタンスタイプで、よりよいコストパフォーマンスを実現できるでしょうか?CSPはAWS EC2 Infなど、推論用に設計された新しいインスタンスタイプを提供しています。AWSによると、EC2 Inf1インスタンスは、Amazon EC2 G4インスタンスよりもスループットが最大30%高く、推論あたりのコストが最大 45% 低くなります。
補足: このインスタンスタイプはまだ新しく、CAST AIとしてはまだこの主張を検証していません。
困ったことに、選択マトリックスはさらに複雑になっていきます。
2. クラウドのコスト削減を念頭に置いてインスタンスタイプを選択する
CSPは、さまざまなユース ケースに合わせて最適化された幅広いインスタンスタイプを提供しています。CPU、メモリー、ストレージ、およびネットワーク帯域のさまざまな組み合わせを提供します。各タイプには複数のインスタンスサイズが含まれており、ワークロードの要件に合わせてリソースを拡張することができます。
AWS と Azure のクラウド請求書を比べてみましょう。それらはもう世界が違います。
CSPはさまざまなコンピュータを運用しており、そのコンピュータに搭載されるチップは、それぞれ異なる性能を持っています。
あなたは、少し低速な旧世代のプロセッサ、または少し高速な新世代のプロセッサを入手している可能性があります。知らないうちに、実際には必要のない強力なパフォーマンス特性を持つインスタンスタイプを選択している可能性もあります。
これを自分で予測することは困難です。これを確認する唯一の方法は、ベンチマークを行うことです。各マシンタイプに同じワークロードを落として、そのパフォーマンスをチェックします。
これは、CAST AIが1年以上前にスタートしたときに、最初に行ったことの一つです。ここに2つの例があります。
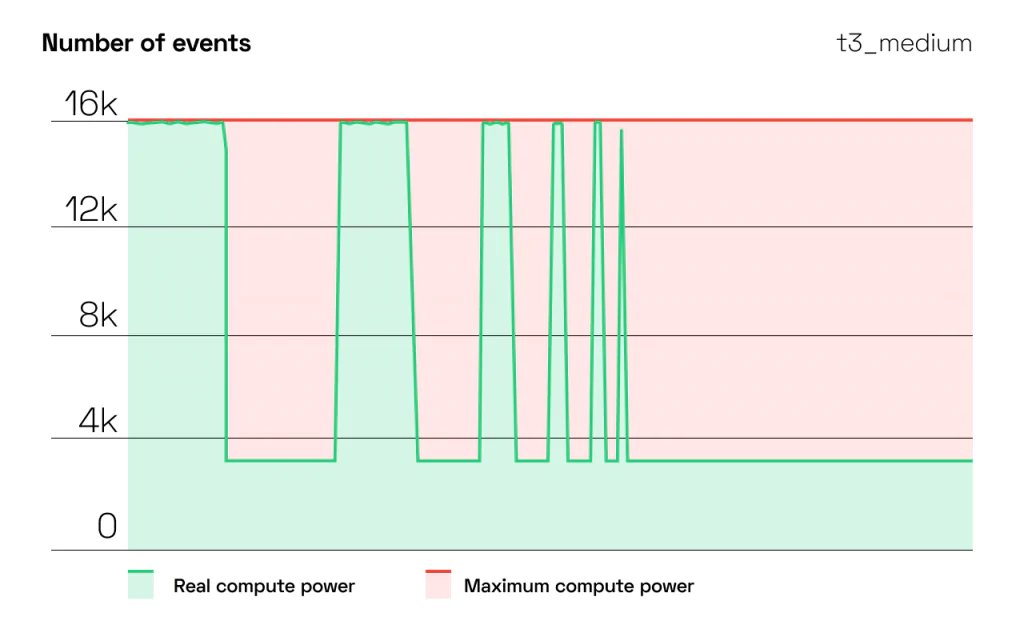
例1: 1つのプロバイダ内であっても予測できないCPU
このグラフは、AWS(Amazon t2-2x large: 8仮想コア)のCPUのアイドル時間を数回設けた後、異なる時間帯にCPUを動作させたものです。
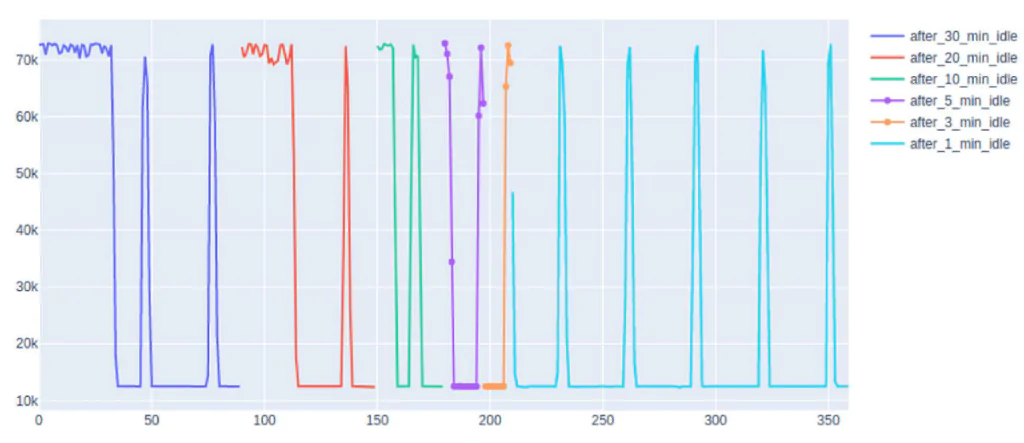
出典:CAST AI
例 2: クラウドの耐久性
VMのパフォーマンスをよりよく理解するために、「耐久係数」という指標を作成しました。その計算方法は次のとおりです。
- VMタイプが12時間でどれだけの仕事をこなせるか、CPUの性能がどれだけ変動するかを測定します。
- 持続的なベースロードの場合は、同じぐらいの安定性が必要でしょう。バースト的なワークロード(たまにトラフィックが発生するウェブサイトや、たまに発生するバッチジョブ)の場合は、安定性は低くても問題ありません。
- シェアードコア、ハイパースレッド、オーバーコミット、世代間、バースト可能なクレジットベースのVMタイプなど、どれだけの安定性が得られるかわからないこともあるので、十分な情報に基づいて判断する必要があります。
- この計算では、性能が安定しているインスタンスは100に近くなり、性能がランダムなインスタンスは0に近くなります。
この例では、DigitalOcean s1_1マシンは0.97107(97%)の耐久係数を達成しましたが、AWS t3_medium_stは0.43152(43%)と変な形になりました - バースト可能なインスタンスではないにも関わらずです。
インスタンスタイプの選択に戻りましょう
WS、Azure、および Google いずれも、次の4種類のインスタンスタイプがあります。
-
General purpose(汎用)
このインスタンスタイプは、CPUとメモリーの比率がバランスよく、トラフィックが低~中程度のWebサーバーや小規模~中規模のデータベースなど、これらのリソースを同じ割合で使用する汎用的なアプリケーションに適しています。
-
Compute optimized(コンピューティング最適)
CPU に負荷のかかるワークロードに最適化されたこの VM タイプは、CPU とメモリーの比率が高くなっています。中程度のトラフィックを発生するウェブサーバー、バッチ処理の前処理、ネットワークアプライアンス、およびアプリケーションサーバーに適しています。
-
Memory optimized(メモリー最適)
このタイプは、メモリーとCPUの比率が高いのが特徴です。そのため、データベースサーバー、リレーショナルデータベースサービス、分析、より大規模なインメモリーキャッシュなどのプロダクションワークロードに適しています。
-
Storage optimized(ストレージ最適)
大量の読み取り/書き込み操作と低レイテンシーを必要とするワークロードは、このインスタンス タイプが適しています。ディスクスループットとIOが高いため、ビッグデータ、SQLおよびNoSQLデータベース、データウェアハウス、大規模トランザクションデータベースと相性がよいです。
また各プロバイダは、異なる名称で GPUワークロード用のインスタンスタイプも提供しています。
AWS
-
Accelerated computing(高速コンピューティング)
これらのインスタンスは、ハードウェアアクセラレーター(コプロセッサ)を用いて、データのパターンマッチング、グラフィックス処理、浮動小数点数の計算などの機能をCPUよりも効率的に実行する。機械学習(ML)やハイパフォーマンス・コンピューティング(HPC)に最適です。
-
Inference type(推論タイプ)
例えば、AWS EC2 Infは、AWS EC2 G4インスタンスと比較して、最大30%のスループット向上と45%の推論単価の低減を約束します。
-
GPU
ほとんどのディープラーニングの目的に推奨されるマシンです。
Azure
-
GPU
Nvidia GPUを搭載したこれらのインスタンスは、重いグラフィックレンダリング、ビデオ編集、計算負荷の高いワークロード、および深層学習におけるモデルの学習と推論(ND)に対応するよう設計されています。
-
High-performance compute(高性能コンピューティング)
このタイプは、計算およびネットワーク集約的なワークロード(ハイパフォーマンスコンピューティングクラスターアプリケーションを含む)用に最適化されたハードウェアを基盤とする、最速かつ最も強力なCPU VMを提供します。高スループットのネットワーク・インターフェイス(RDMA)との組み合わせに最適です。
-
Accelerator-optimized(アクセラレータ最適)
NVIDIA Ampere A100 Tensor Core GPUをベースにしたこれらのVMは、1つのVMで最大16個のGPUを使用することができます。HPCやCUDA対応の機械学習(ML)のトレーニングや推論など、要求の厳しいワークロードに最適です。
詳細については、次のリンクを確認してください。
ARM搭載VMに関する特記事項
最近、ARMベースの新しいSOC(System-on-Chip)であるApples M1シリーズが2020年11月に発表され注目されています。アップルによると、M1によってCPUの性能は3.5倍、GPUの性能は6倍になるそうです。ARMアーキテクチャをベースにしており、信じられないほど高速です。クラウドプロバイダは、同社のARMプロセッサ「Graviton2」を搭載した「AWS EC2 A1」ファミリーのように、ARMを搭載したVMを提供しています。
ARMについて知っておくべきことは次のとおりです:このタイプのプロセッサは、消費電力が低いため、動作コストや冷却コストが低く、CSPの料金も安くなります。しかし、このプロセッサを使用しようとする場合、アプリケーションをARM用にコンパイルするために、デリバリパイプラインを再設計しなければならない場合があります。Python、Ruby、NodeJSなどのインタプリタ型スタックで実行している場合なら、アプリケーションは単に実行するだけですみます。
3. さまざまな価格モデルの長所と短所を検討する
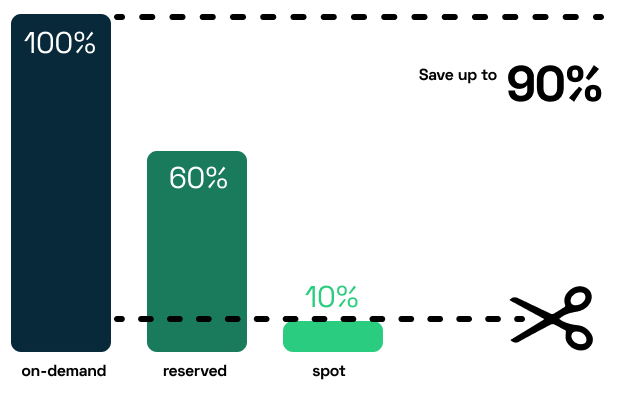
次のステップは、ニーズに適した価格モデルを選択することです。クラウドプロバイダは、次のモデルを提供しています。
- 1. オンデマンド
このモデルでは、使用したリソースに対して料金を支払います(たとえば、AWSでは計算能力を時間単位で課金します)。長期契約や前払い金はありません。使用量はジャストインタイムで増減できます。このような柔軟性があるため、オンデマンドインスタンスは、トラフィックが急激に増加するワークロードに最適です。 - 2. リザーブドインスタンス(GCPでは、確約利用割引)
リザーブドインスタンスは、オンデマンドインスタンスよりもはるかに低価格で、特定のアベイラビリティゾーンの容量を前もって購入することができます。ほとんどの場合、特定のインスタンスまたはファミリーにコミットし、後で要件が変更されても変更することはできません。一般に、前払い金が多いほど割引率は高くなります。コミットメントの期間は、1年から3年です。 - 3. Savings Plans(AWS)
このモデルでは、1年または3年の間に特定の計算能力(1時間あたりのドル換算)を使用することを約束することで、Reservedインスタンスと同じ割引を受けることができます。1時間あたりの使用量を約束すると、それまでの使用量はすべてSavings Planでカバーされ、それ以上はOn-demand料金で請求されます。リザーブドインスタンスとは異なり、特定のインスタンスタイプや構成(OSやテナンシーなど)を約束するのではなく、一貫した利用を約束するものです。
しかし、そもそもCAPEX(資本的支出)を避けるためにパブリッククラウドにしたのではなかったのでしょうか?リザーブドインスタンスやAWSのセービングプランを選択することによってクラウドベンダロックのリスクと、1年後、2年後には意味がなくなるかもしれないリソースを確保するリスクを負うことになります。クラウドの世界では、3年というのは永遠と同義です。
これはCSPの悪習です。彼らは割引によって顧客を取り込み、今後何年にもわたって代替手段から隔離します。
- 4. スポット インスタンス(GCPではプリエンプティブル)
この価格モデルは、予備のコンピューティングリソースを入札で購入するものです。これにより、クラウドのコストをオンデマンド価格の最大90%まで削減することができます。スポットインスタンスの問題点は、可用性が保証されないことです。可用性は、特定の地域の現在の市場需要によって変化します。スポットインスタンスは、ワークロードが中断に対応できる場合(例えば、マイクロサービスのようなステートレスなアプリケーションコンポーネントを使用している場合)には、理にかなっていると言えるかもしれません。 - 5. 専有ホスト(GCPでは単一テナントノード)
専有ホストは、完全にお客様専用のインスタンス容量を持つ物理サーバーです。お客様専用のライセンスを使用することで、コストを削減しながらも、クラウドベンダーの持つ回復力と柔軟性を活用することができます。また、コンプライアンス要件を満たす必要がある企業や、ほかのテナントと同じハードウェアを共有したくない場合にも適しています。多くの機密データを扱う規制市場では、セキュリティ上の利点から専有ホストを選択することがよくあります。
注意: 追加料金について忘れないでください。AWS、Azure、GCP はすべて、送信トラフィック、ロードバランサー、ブロック ストレージ、IP アドレス、プレミアムサポートなどの項目に対して課金されます。インスタンスの価格を比較し、クラウドの予算を立てる際には、これらの項目を考慮に入れてください。
そして、それぞれの項目には注意する必要があります。
送信トラフィックを例にします。単一クラウドのシナリオでは、異なるアベイラビリティゾーン間の送信コストを支払う必要があります。これは、ほとんどの場合、$0.01/GB です。マルチクラウドの構成の場合、ダイレクトファイバーを使った場合(米国/EU の場合)は 0.02 ドルとなり、わずかですが高い料金を支払うことになります。
4. CPUバーストを活用する
各 CSP を詳しく見てみると、「バーストパフォーマンスインスタンス」があるはずです。
このインスタンスは、基本的なCPUパフォーマンスを提供し、ワークロードが必要とするときに高いレベルにバーストするオプションがあるように設計されたインスタンスです。低レイテンシーのインタラクティブなアプリケーション、マイクロサービス、中小規模のデータベース、製品のプロトタイプなどに適しています
備考:CPUクレジットの蓄積量は、インスタンスタイプによって異なります。インスタンスが大きいほど、1 時間あたりにより多くのクレジットが収集されます。ただし、収集できるクレジット数にも上限があり、インスタンス サイズが大きいほど上限が高くなります。
バーストパフォーマンスインスタンスはどこで入手できますか?
AWS
- インスタンスファミリー: T2、T3、T3a、および T4g
- T2 ファミリーでインスタンスを再起動すると、蓄積されたすべてのクレジットが失われます。
- T3 および T4 でのインスタンスの再起動 = クレジットは 7 日間存続し、その後失われます。
Azure
- CPU バーストの B シリーズ VM
- VM を再デプロイして別のノードに移動すると、クレジットが失われます。
- VM を同じノードに保持したまま VM を停止/起動すると、蓄積されたクレジットが保持されます。
GCP
- 共有コア VM はバースト機能を提供します: e2-micro、e2-small、e2-medium
- CPU バーストは、f1-micro、g1-small、e2共有コアマシンタイプのオンデマンド料金で課金されます。
AWSを調査した結果、1日平均4時間以上インスタンスに負荷をかける場合は、バーストしないものの方が良いことがわかりました。しかし、たまに訪問者が殺到するようなオンラインストアを運営しているのであれば、相性が良いと思います。
備考: CPU 容量には制限があります
最初の4時間は、計算能力が直線的に増加する傾向があることがわかりました。しかし、それ以降は、かなり制限されるようになります。1日の終わりまで、利用可能なコンピュート量はほぼ90%減少します。
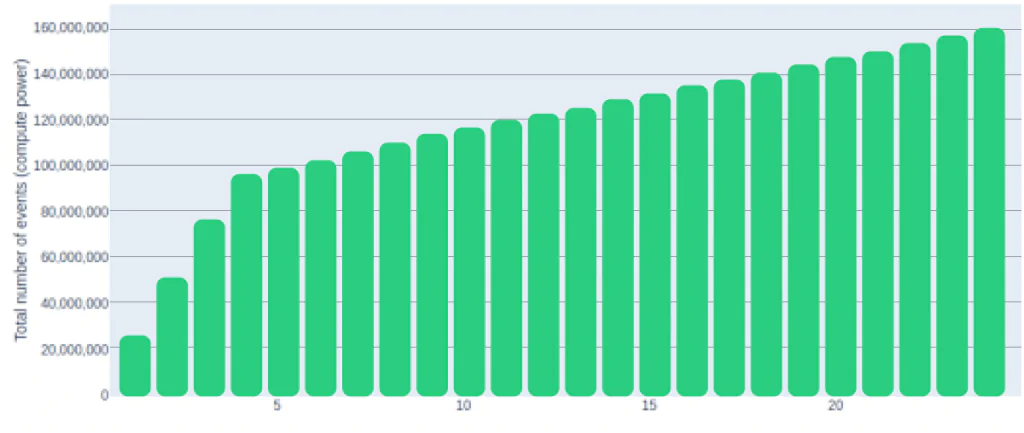
出典:CAST AI
5. ストレージの転送制限を確認する
クラウドのコスト削減を最大化するためにもう一つ考慮すべきなのが、データストレージです。
- AWS EC2 インスタンスは Elastic Block Store(EBS)を使用してディスク ボリュームを格納します。
- Azure VM はデータディスクを使用します。
- GCP はブロックストレージ用の Google Persistent Disk があります。
- AWS、Azure、GCPではローカル一時ストレージを利用できます。
すべてのアプリケーションには、固有のストレージニーズがあります。VM を選択するときは、アプリケーションが必要とするストレージスループットを備えていることを確認してください。
また、プレミアムSSDのような高価なドライブオプションは、最大限に活用することを想定していない限り、選択しないでください。
6. ネットワーク帯域幅をカウントする
データの大移動や大量のトラフィックが発生する場合は、インスタンスとそのインスタンスに割り当てられたコンシューマとの間のネットワーク接続のサイズに注意してください。10Gbpsや20Gbpsの転送速度が出せるインスタンスもあります。
しかし、ここで注意しなければならないのは、このレベルのネットワーク帯域をサポートするのは、これらのインスタンスだけだということです。
クラウドコストの節約 - ケース スタディ
先日、Googleから転用したオープンソースのECデモアプリで、CAST AIのアプローチによるクラウドコスト削減を検証しました。
行ったことは次のとおりです。
-
意味のある利用料金となるよう、多数の同時接続ユーザー(最大1000)を使ってアプリケーションの負荷テストを行いました。
-
そして、各マイクロサービスのポッドを適宜スケーリングしていきました。これは、AWS EKS上で静的にスケーリングされたデプロイメントで行われました。
-
メトリックを取得するために、30~60 分間テストを実行しました。
-
次に、想定されるトラフィックの季節性を考慮して、30 日間のコストを推定しました。負荷テスト スクリプトの一部として、30 日間の使用パターンを生成しました。
-
その結果、毎日ほぼ同じ時間に使用量が急増し、週の数日間はトラフィックがやや重くなりました。
このように、AWSのテストクラスタ上でアプリを実行した場合の月額コストを算出し、クラウドのコスト削減効果を高めるためのソリューションを比較検討しました。
なお、今回のデモシナリオでは、元のEKSクラスタのサーバー数は固定で、インスタンスタイプはm5.xlargeを想定しています。元のクラスタは、オートスケーリングやスポットインスタンスを使用していません。
当初は、4CPU、16GBのメモリー、高スループットのネットワークインタフェース(~10GiB)を備えたm5.xlarge VMを選択しました。このインスタンスタイプのオンデマンドのコストは、$0.192/時間です。
自動分析により、オプティマイザーは代替のタイプとなるa1.xlargeを選択しました。このインスタンスタイプは、4つのCPUと8GBのRAMを備えています。VMごとにデプロイされるPodは、簡単に8GBに収まりました。以前のインスタンス(m5.xlarge)の追加8GBは、純粋なRAMの無駄遣いでした。アプリを再コンパイルし、新しいコンテナイメージを構築することで、a1(ARM)プロセッサを選択することができました。
新しいインスタンスでは、ネットワークのスループットが低下していました。私たちのアプリでは、ネットワークに縛られていなかったので、これは問題ではありませんでした。つまり、利用可能な計算リソースで生成されたトラフィックが、選択したインスタンスの帯域幅の容量を最大化することはなかったのです。
そして、ここからが一番の見せ場です:
a1.xlargeインスタンスのコストは、わずか0.102ドル/時間です。つまり、計算時間あたり46%のクラウドコスト削減を即座に達成したことになります。

まとめ
クラウドプロバイダに求めるのは「コンピューティング」です。クラウド料金の中で最も大きな割合を占めています。ですから、この部分のコストを最適化することができれば、クラウド料金を劇的に削減することが可能になります。

オラクルのセキュリティ製品OCIの元副社長であるLeonは、IBM、Truition、HostedPCIなどの企業にまたがる20年余りの経験があります。
LeonはZenedgeを設立し、Oracleに買収されたCTOを務めました。
タグ一覧