この記事は、CAST AI社により公開されたブログ記事を元に翻訳・作成したものです。
(記事最終更新日:2023年4月27日)
Gen AIと大規模言語モデルのトレーニングと推論: AWSの請求額を減らす方法
公開日:2023年6月29日
更新日:2023年6月29日
AIソリューションの構築は、ビジネスに大きな影響を与える可能性があるとてもクールなチャレンジです。しかし、どの財務担当者に聞いても、即座にそのリスクを指摘するでしょう。AIソフトウェアのマージンは、一般的なSaaSよりも小さくなります。これは、AIがそのメーカーとユーザーの両方に課す計算量がとても高いためです。

生成・大規模言語モデル(LLM)のトレーニングと実行(推論)にかかる膨大なコストは、過去の技術的進歩とは異なるコスト構造です。このタイプのAIモデルは、プロンプトに応答するたびに、何十億もの計算をするため、膨大な計算資源が必要となります。
このような計算には、特殊なハードウェアも必要です。従来のコンピューターのプロセッサーでもMLモデルを実行できますが、非常に低速になります。そのため、ほとんどのトレーニングや一部の推論では、さまざまなデータセットの並行処理に最適なGPUインスタンスで行われます。
クラウドコスト管理ソリューションは、特にKubernetesを使用する場合、トレーニングや推論にかかるコストをさまざまな面から削減できます。
この記事を読み進めて、その方法を知ってください。
モデルのトレーニングと生成コストの削減
多くの企業がKubernetesを使ってアプリケーションをコンテナー化していますが、その中にはAIモデルも含まれています。ここで1つ注意点があります。Kubernetesのスケジューリングでは、ポッドが正しいノードに割り当てられるように動作しますが、このプロセスは可用性とパフォーマンスがすべてです。また、費用対効果については考慮されません。
特にGPUを多用するアプリケーションでは、Kubernetesポッドが高額なノードを半分しか使わないようなことも発生します。このような不適切なスケジューリングは、高額なクラウド請求書を容易に生み出します。
しかし、このようなクラウド料金の高騰を防止するために、できることがあります。
ノードテンプレートによる自動スケーリング
あるお客さまのこの問題を解決するために、トレーニング用のコスト効率が良いGPUノードをプロビジョニングし、スケーリングする仕組みを開発しました。
CAST AIのオートスケーラとノードテンプレートは、エンジニアが手作業で行わなければならないプロビジョニングプロセスを自動化します。
ワークロードを、あらかじめ定義したインスタンスグループ上で実行できます。エンジニアは、特定のインスタンスを手動で選択する必要はなく、「GPU VM」のような大まかな特性を定義するだけで、オートスケーラが自動で対応します。マシンの選択肢を広げることは、現在のサーバー不足を考慮すると、賢い選択と考えることができます。
GPUジョブが完了すると、CAST AIオートスケーラはGPUインスタンスを破棄し、コスト効率が良いインスタンスに置き換えます。この作業はすべて自動で行われ、誰も指1本動かす必要はありません。
この機能の詳細を知りたい場合には、ドキュメントを参照してください。
推論するためのCPU/GPUのスポットインスタンス最適化とオートスケーリング
スポットインスタンスは、AWSで最も費用対効果が高いインスタンスオプションで、オンデマンド価格から90%削減できる可能性があります。しかし、わずか2分の警告で、いつ中断されるかわかりません。Google CloudとAzureの場合は、警告時間はさらに短く30秒です。
CAST AIは、スポットインスタンスをライフサイクルの各段階で自動化する仕組みを用意しています。
このプラットフォームは、モデルの計算要求に最適なポッド構成を特定し、ワークロードとして必要な基準を満たしつつ、市場で最も安価なインスタンスファミリーから仮想マシンを自動的に選択します。
CAST AIは、ワークロードの需要を満たすスポットキャパシティが見つからない場合、スポットフォールバック機能を使って、スポットインスタンスが利用可能になるまで、オンデマンドインスタンスでワークロードを一時的に実行します。それが発生した後に、ユーザーからのリクエストがあれば、ワークロードをシームレスにスポットインスタンスに戻すこともできます。
よりスマートなワークロード実行計画のための価格予測
CAST AIは、最先端のMLモデルを使って季節性やトレンドを予測する価格設定アルゴリズムを備えており、バッチジョブを実行する最適なタイミングを決定することが可能です。コンシューマーがワークロードをすぐに実行する必要がない場合、はかなりのコスト削減をもたらします。
例
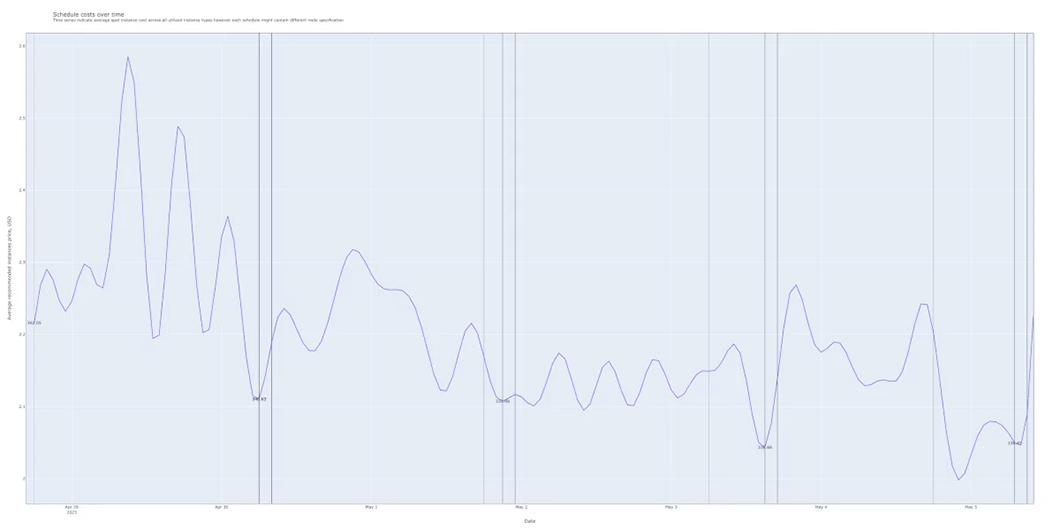
この簡易チャートでは、2つの異なるタイプのEC2インスタンスを使用して、単一のワークロードを実行した場合の価格が示されています。When-to-Runモデルにより、CPUやメモリーの要求量、将来の価格見通しなどの情報から、最適なポッド構成を算出しています。
チャートのX軸は日付、Y軸は1回のワークロード実行時間の合計金額です。もし、すぐにワークロードを実行するのであれば、1回の実行につき、360ドルを支払うことになります。数日待つと、そのワークロードは5%安くなります。
このような利点が組み込まれているため、チームはクラウド予算を効率的に計画でき、その結果、スポットインスタンスの充足率が大幅に向上し、節約効果が高まります。
CAST AI がEKSでAIモデルのトレーニング、および実行をするお客さまで、76%のクラウドコストを削減
ケーススタディを読むAWS Inferentiaをサポート
INFは、もし、チームが同社のSDK/ランタイムを使用しているならば、推論のためが素晴らしいプロセッサーです。CAST AIは、このタイプのインスタンス用にノードテンプレートを作成できます。AWSは、深層学習のユースケース専用に構築されたInferentiaの最新バージョンINF2をリリースしました。
Inferentiaのプロセッサーをご存じない方のために、ここで簡単に説明します。
AWS Inferentiaは、さまざまなアプリケーションで高性能かつ低コストの推論を実現するために構築された、目的別ML推論プロセッサーのファミリーです。これらのプロセッサーは、推論ワークロード用に最適化されたカスタムビルドの深層学習推論エンジンを介してDNNを処理するときに、非常に効率的であるように設計されています。このエンジンは、ResNet、VGG、LSTMなど、多くの一般的なニューラルネットワークアーキテクチャをサポートしています。
これらさまざまな構成のInferentiaプロセッサーを利用して、Amazon SageMakerやAWS Deep Learning AMIなどのAWSサービスと組み合わせて、ML推論ワークロードのディプロイやスケールができます。
Nvidiaドライバーの設定をより簡単に
さらに、CAST AIは、Nvidiaドライバーのインストールから設定まで、Nvidiaドライバー周りのすべてのメンテナンスを実施します。設定を誤ると、GPUではなく、CPUが使用される可能性があるため、このことは重要なポイントになります。このことは、エンジニアの時間をより重要な業務に使うことができます。
Next steps: タイムスライスとその他の機能
大規模なAIモデルを構築し、実行するチーム向けに、将来的に追加を予定している機能の1つに、GPUタイムスライスがあります。
GPUタイムスライシングは、1つの物理GPUを複数のKubernetesポッドで共有するために、用いられる技術です。各ポッドにはGPUの処理能力の一部が割り当てられるため、1つの物理GPUで複数のアプリケーションを同時に実行することが可能です。
このことは、リソースが複数のユーザーまたはアプリケーション間で共有されることが多いクラウド環境で特に有効です。GPUタイムスライスを利用することで、プロバイダーはより多くのユーザーにGPUアクセラレーションを提供し、各ユーザーにGPUの処理能力を公平に配分できます。
GPUタイムスライスの主な利点は、ユーザーが独自の専用 GPU インスタンスを割り当てることなく、GPUアクセラレーションされたアプリケーションを実行できるため、GPUアクセラレーションされたワークロードの実行コストが削減できることです。
AI/MLのクラウド支出を削減しましょう
CAST AIは、コンピューティングリソースを継続的に分析・最適化し、あらゆる段階でエンジニアをサポートするKubernetes管理プラットフォームです。
ご使用のクラスターに接続するだけで、提案されたレコメンデーションを見ることができ、AIプロジェクトのコストを削減するために、その提案をすぐに自動で実装できます。
GPUワークロードのユニークなユースケースをお持ちの方、GPUを多用するワークロードの効果的なスケーリングにお困りの方は、ぜひお声がけを頂戴できればと思います。


オラクルのセキュリティ製品OCIの元副社長であるLeonは、IBM、Truition、HostedPCIなどの企業にまたがる20年余りの経験があります。
LeonはZenedgeを設立し、Oracleに買収されたCTOを務めました。
タグ一覧